Sentiment analysis using Deep Neural Nets
In an earlier post, we explored how to use tidy text and QDAP to perform sentiment analysis in R. This post will make use of Convolutional Neural Network (CNN) along with word embeddings to perform sentiment analysis on IMDB movie reviews. Later in the post, we will explore whether the same network can be used to classify sentiment of text from a somewhat different domain (movie subtitles and reddit comments).
IMDB Movie Sentiment
We make use of IMDB movie review dataset which contains 25K reviews for training and 25K for the test. The overall process is broken into three categories: Preprocessing, Neural Network Architecture and Performance. We start with preprocessing step that converts the data into a format that our Neural Network can understand and work with. Then, we search for a Neural network architecture that performs well on the test set.
The preprocessing steps include:
- Clean up: remove unwanted characters such as exclamation, hyphen, open and close brackets, angular brackets etc
- Build a vocabulary of words and drop less frequent words
- Convert word into integer representation, this is required because Neural Networks work on numbers
- Convert each review into fixed length vector
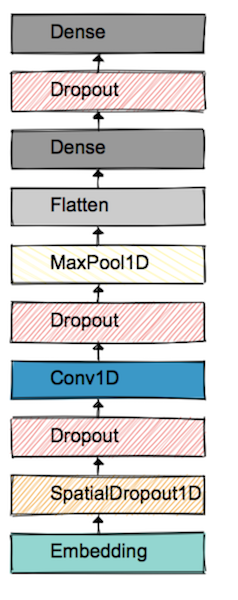
Once we have the preprocessed data, we begin experimenting with network architecture and choose the one that performs well on both train and test set. The architecture shown here worked well in my tests. My jupyter notebook covers other architectures as well.
Overall, our network gained from two main choices: Word Embeddings and Dropout. By now, we have a trained model ready for our experiments. Let’s play.
Movie Subtitles Sentiment
In this experiment, we classify movie subtitles into positive and negative sentiment. We want to find out the performance of our trained model by reviewing subtitle and its predicted sentiment. The sigmoid activation on the final layer outputs a float between 0.0 and 1.0. In our case, predictions closer to 0.0 imply negative sentiment and the ones closer to 1.0 imply positive sentiment. The predictions near 0.5 means that the network is not sure whether to classify negative or positive.
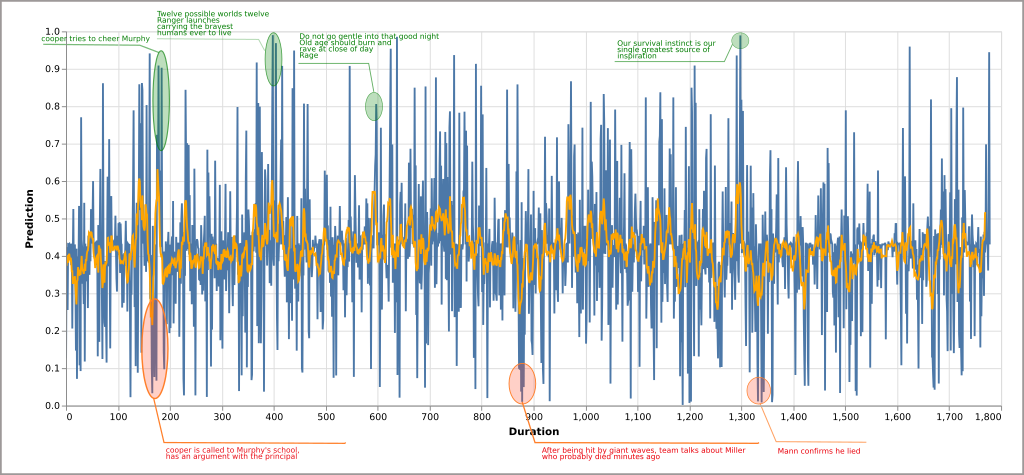
We run the classifier on subtitles from the movie Interstellar and generate a line chart. The blue line is the sentiment of each line and orange shows the rolling mean of 10 lines. With this approach, the classifier encounters many lines with very few words such as “Okay Yeah”, “Uh hey”, “Yes”, “No” and usually predict between the range 0.45 and 0.5. The classifier doesn’t seem to perform too bad but it does have difficulty classifying short lines.
Marvel vs DC
In the movie Deadpool, Wade Wilson tells Cable “So dark! You’re sure you’re not from the DC Universe?”
Let us ask our neural network.
We gather subtitles from all the movies that are part of Marvel and DC Cinematic Universe, run our classifier and categorize each subtitle into negative, positive or neutral/undecided. A subtitle is considered positive if its predicted value (sigmoid output) is greater than 0.5, negative if the value is less than 0.4 and neutral if it is between 0.4 and 0.5. As with heuristics, the boundary conditions were chosen based what seemed to work best in my limited tests.
The Wonder Woman movie seems to contain the most negative sentiment. The classifier was largely confused by Captain America Winter Soldier as most of its predictions resulted in the neutral/undecided area. I expected Batman vs Superman to show up as the one with the most negative sentiment, or was it just a terribly made movie?
Reddit Comments Sentiment
We use the same classifier, that was trained on IMDB movie reviews, and run it on comments taken from Reddit dataset. The comments below are color-coded with green as positive, gray as neutral/undecided and red as negative. The model seems reasonable in identifying negative comments but fails to detect sarcasm.
Disclaimer: I do not support or endorse any of the following comments made on Reddit and my only intention is to use them as an example to test classifier.
subreddit: worldnews | reddit score: -13
Guilty as charged. I just had a feeling that if I didn't do that reddit would take this as a pro-war story and. well, down vote it to hell
subreddit: news | reddit score: -45
WWIII was the cold war. Get a basic grip on history
subreddit: xkcd | reddit score: -17
When you do an exact copy of something and change absolutely nothing but the name, how is that not stealing?. This is not a variation on the theme of graph-based comic. It's straight up plagiarism
subreddit: xkcd | reddit score: 16
Agreed. Nerd rage can be quite powerful. Almost had to put my velociraptor t-shirt on for emphasis
subreddit: gaming | reddit score: 19
Shhh, shhh, quiet for a second. Listen. You hear that? That very faint noise? That was the sound of a joke flying over your head
subreddit: science | reddit score: 14
But I still do not understand how do the GPS satellites know their location! They do not triangulate themselves with respect to quasars, do they?. Any GPS engineer to rescue? Thanks!
subreddit: science | reddit score: 19
according to the comments on youtube: Water is diamagnetic and frogs are mostly water. Diamagnetic compounds have a weak repulsive reaction to magnetic fields that is overpowered by the presence of paramagnetic or ferromagnetic fields. Look if up, if you doubt me. So therefore, imagine all the water in you being pushed up while the rest of you still has gravity pulling it down.
Okay, the last two comments left the classifier clueless, and me too.
Conclusion
We trained a Neural network on IMDB movie reviews and tested it on text from different domain. Apart from domain, the input size was different too. The network was trained to classify review of 500 letters as positive or negative whereas in our testing we used it on sentence level classification.
We saw that it did not perform well on reddit comments. It also performed poorly on sarcastic comments, perhaps the reviews weren’t sarcastic enough. More than often, the predictions were between 0.4 and 0.5 which indicate that network was not very certain about the sentiment.
My goal with these experiments was to find out how far we can go with the IMDB model. Not very far, it seems to work on sentences such as “I like simple things in life” but fails to classify “These candies are delicious” correctly. It will be interesting to train a classifier on tweets and compare its performance with the IMDB model. And yes I do agree with what you are thinking, we could improve the classifier by generating domain specific training data.
The question then is, whether we can use transfer learning in NLP tasks similar to computer vision, where we train a base model on imagenet and fine tune on task specific datasets. What would be the imagenet equivalent for NLP? This is an active area of research and new papers such as Deep contextualized word representations show us one of the ways forward.