Using Attention to Improve Neural Image Caption Generator
Introduction
In this post, I attempt to explain the attention in Neural networks in the context of image captioning. And, how it improves the model performance and provides some interpretability. We will manually inspect the captions generated by the vanilla model against that of the attention powered one. We will also glance through the automatic evaluation criteria used for comparing models in the NLP world and review the pros and cons of using such evaluation metric.
Recollect that, in the previous post, we used vanilla seq2seq architecture to create a model that could caption the images. The seq2seq architecture has two parts: encoder and decoder. We use the encoder to convert the input image into a low dimension image vector. The image vector is then used by the decoder to generate the captions. The decoder generates the caption by producing a single word at every time step. This is done using a combination of word generated at the previous step and the image vector. It continues to do so until it reaches the end of sentence marker or a pre-defined max number of timesteps.
We will make many references to the neural machine translation (NMT) because innovations such as seq2seq, attention were introduced there. These were later adopted by other domains in NLP as well as Computer Vision.
Motivation
In NMT, we pass the source sentence through the encoder one word at a time. At each timestep, the encoder updates its hidden state, and we expect the final hidden state to encapsulate enough information to allow the decoder to generate the translation. The decoder makes use of the along with its own internal hidden state , to generate one word at a time. We seem to be asking a lot from the final hidden state of encoder, and indeed, the layer highlighted in red is the information bottleneck.
We visualise the NMT architecture below with input in the Sanskrit language and its English translation.
The input source is taken from the Bhagavad Gita, the ancient Sanskrit scripture, that talks about focusing on the process rather than the results

Example of seq2seq NMT model
If you and I were to caption an image, we would most likely look at specific parts of the image as we come up with the caption. In contrast, our model looked at the entire image (vector) at every timestep. What if we could teach the network to focus on certain parts instead? Similarly, in NMT, what if the decoder could access all the hidden states in encoder and somehow learn to decide how much should it focus on each to generate the next word in target language. And, this motivates the concept of attention in neural networks.
Attention
Attention allows the neural network, the decoder in case of image caption, to focus on the specific parts of the image as it generates the caption. Before we see how it is done, let’s visualise attention using the cartoon below.
Click on the play button to see the animation
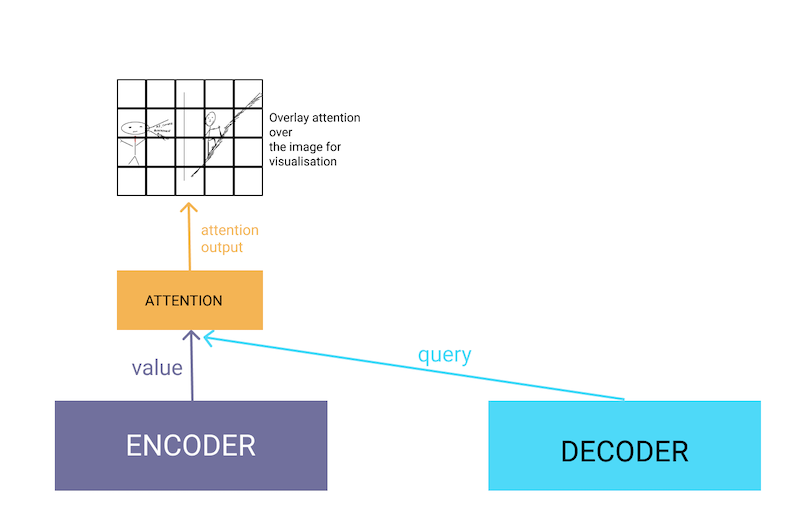
We overlay the attention heatmap to visualise what parts are in focus at each timestep. As you can see, the decoder now focuses on certain parts of the image as it decides the next word. At this point, I must emphasize that without attention, the decoder in previous, used the entire image vector.
The hidden state of decoder is called query, and the hidden state of encoder is called value. In our case, the value is simply the image vector (i.e the output of CNN based encoder). We calculate attention using the hidden state of decoder at a particular timestep and the entire image vector from the CNN based encoder. With that, its time for the definition:
Attention is the weighted sum of values dependent on the query
In the case of NMT seq2seq, usually, both encoder and decoder are some variants of RNN and hence have internal hidden states. The decoder makes use of hidden states from all steps (, , …, ) to calculate attention score. This means that decoder is no longer restricted by the limitations of relying on the final hidden state . Thus, attention provides a solution to the information bottleneck problem we saw earlier.
General Framework
There are several variants of attention, but the process of generating attention generally follows the following three steps:
-
Attention Score: Calculate attention score, , using the hidden state of encoder and the hidden state of decoder
-
Attention Distribution: Calculate attention distribution using softmax over all hidden states
-
Attention Output: Calculate attention output, also known as context vector, by taking the weighted sum of the encoder hidden state and attention distribution
We then concatenate attention output and the decoder hidden state and continue with rest of the forward pass depending on the architecture. In this case, we kept the architecture same as the vanilla seq2seq model, GRU to fully connected.
These steps are discussed in the context of NMT but are also applicable to the image caption model. Instead of encoder hidden state, we just make use of image vector.
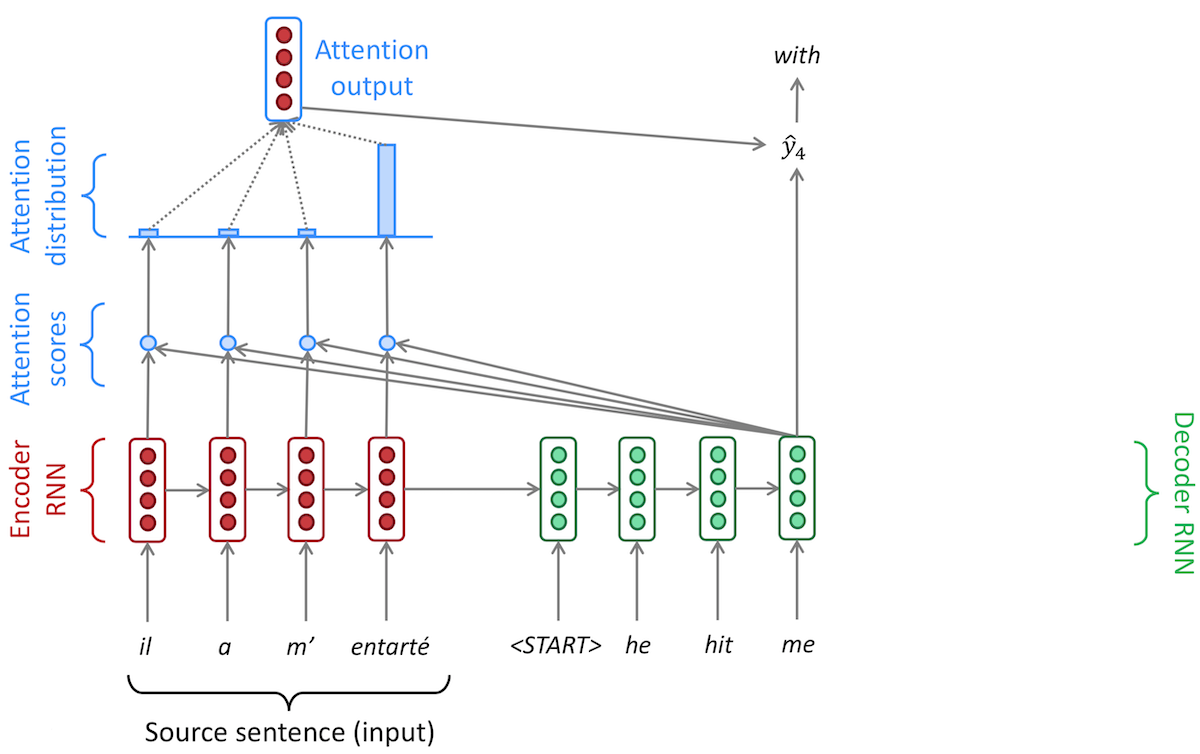
Source: XCS224N Lecture 8 Slide
Types of Attention
There are several ways to compute the attention score. In this post, we cover three common ones listed below. If you’re interested in learning more, I recommend this detailed post on attention mechanisms (e.g Hard vs Soft attention, Global vs Local attention).
Dot Product Attention
The most basic but fastest form of attention in terms of compute. We calculate the attention score using decoder hidden state and the hidden state for every step and summing them together. This requires the encoder and decoder hidden state dimensions to be the same i.e. :
Multiplicative Attention
In this case, we make use of a weight matrix to compute the attention score. This allows the dimensions and of encoder and decoder hidden states to be different. The weight matrix is learned during the training phase:
Additive Attention
This form makes use of two weight matrices and along with the weight vector . The weight matrices are learned during the training phase:
Examples
In this section, we compare the captions generated by vanilla seq2seq from the previous post against that of attention powered model and the human baseline, that was created by an 8-year-old. Choose the decoding algorithm from below and hover over the image to see the captions.












Hover over the image to view the captions
In my experiments with decoding algorithms, Pure Sampling Decoder and Top-K Sampling Decoder tend to generate better captions.
Benefits
Attention greatly improves the model performance by allowing the decoder to focus on certain parts of the encoder. In the NMT vanilla seq2seq model, only the last hidden state of the encoder is used to generate the translation, which causes the information bottleneck situation. Attention solves this issue by providing direct access to all states, which in turn also solves the vanishing gradient problem. This is similar to how resnets solve it by providing skip-connections. We also get some interpretability because we can now see what parts of the input were responsible for a particular word in the caption. In the example below, we overlay attention output over the input image.
Example Visualizations
Visualising attention as the model generates the caption: Herd of cattle are walking in a field with lots of grass
From my lecture notes
Evaluation
We did not cover any evaluation metrics while comparing the performance of vanilla and attention-based model. There are a few evaluation metrics used in the Machine Translation world that are useful; one of them is Bilingual Language Evaluation Understudy (BLEU). BLEU generates a score between 0 and 1 by comparing the generated caption against the gold standard reference sentences (i.e human-generated caption). For simplicity, let us assume we have a single generated sentence G and the reference sentence R. We can then calculate BLEU score using below:
-
Calculate n-gram precision score where
Calculate the precision score for unigrams:
let be the count of unigrams in G that exist in R and be the count of all unigrams in R
we then calculate precision score using
-
Calculate the precision score for all n-grams yielding and
-
Calculate the geometric mean of n-gram precision score
-
Apply brevity factor to penalise short sentences where c is the length of model generated caption and r is the length of reference sentence. As you can see in the image samples above, I was unable to apply brevity factor on the baseline human captions.
-
The BLEU-4 score then is .
Below is the non-exhaustive list of pros and cons of using BLEU as an evaluation metric:
| PROS | CONS |
|---|---|
|
|
The model with a high BLEU score is considered good on the leaderboards. And naturally, people started to optimize their models to achieve high BLEU scores. As a result, the models started to attain high BLEU scores, but their correlation with human performance diverged. In other words, the improvements in BLEU score did not translate in improvements against human performance. Rachael Tatman covers BLEU and its pitfall in detail here.
Conclusion
We introduced the concept of attention in neural networks by choosing an existing baseline model and improving it. We observed that attention powered model generated better captions, as shown in the image samples above. We then reviewed a few basic kinds of attention. We found that we could reuse the baseline model architecture and retrofit attention specific logic to it. We also found that attention provided added benefit of interpretability by overlaying the attention output over the input image.
Overall I found that model generated captions are still not as good as human counterparts and still require quite a bit of work. Some of the ideas to improve the performance include improving the data domain, tuning hyperparams and experimenting with different architectures.

Judging by the recent trend in the NLP world, it turns out that Attention is all you need.
TODO Share the code and notebook
REFERENCES
[1] Generating Captions using Neural Networks [BLOG]
[2] Stanford Advanced AI Course: XCS224N - Natural Language Processing with Deep Learning
[3] BLEU Paper [PDF]
[4] Attention blog [LINK]
[5] Re-evaluating the Role of BLEU in Machine Translation Research [LINK]
[6] Evaluating Text Output in NLP: BLEU at your own risk [LINK]
[7] Tensorflow NMT Notebook [LINK]
[8] Effective Approaches to Attention-based Neural Machine Translation [LINK]
[9] Neural Machine Translation by Jointly Learning to Align and Translate [LINK]
[10] Beyond Narrative Description: Generating Poetry from Images by Multi-Adversarial Training [LINK]