In this post, we are going to solve Tennis, a unity ml-agent environment, using the approach presented in the paper "Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments".
Tennis
In this environment, two agents control rackets to bounce a ball over a net. If an agent hits the ball over the net, it receives a reward of +0.1. If an agent lets a ball hit the ground or hits the ball out of bounds, it receives a reward of -0.01. Thus, the goal of each agent is to keep the ball in play.
The observation space consists of 8 variables corresponding to the position and velocity of the ball and racket. Each agent receives its own, local observation. Two continuous actions are available, corresponding to movement toward (or away from) the net, and jumping.
The task is episodic, and in order to solve the environment, the agents must get an average score of +0.5 (over 100 consecutive episodes, after taking the maximum over both agents). Specifically,
- After each episode, we add up the rewards that each agent received (without discounting), to get a score for each agent. This yields 2 (potentially different) scores. We then take the maximum of these 2 scores.
- This yields a single score for each episode.
The environment is considered solved, when the average (over 100 episodes) of those scores is at least +0.5.
Agents playing the game using trained policy
Overview
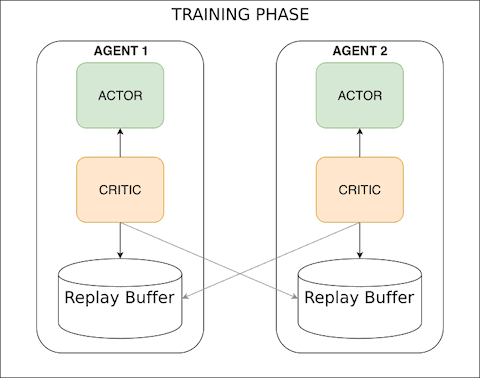
The solution used in this post makes use of the approach presented in the paper "Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments". We use Actor-Critic networks, same as Deep deterministic policy gradients post, but instead of training each agent to learn from its own action, we incorporate actions taken by all agents. Why use actions taken by all agents to train the single agent ? Because, the environment state depends on the actions taken by all agents (i.e non-stationary from a single agent's perspective) so if we just train the agent using its own action, the policy network does not get enough information to come up with a good policy and most likely will take longer to find any good policy. Having said that, It is possible to solve this environment by training each agent just using its own action (i.e DDPG), see my implementation here.
Going back to Multi-Agent Actor-Critic paper, the action from each agent is used only during the training phase to ease the training (centralised training). During execution, we just use the the policy network that returns the action for a given state. We do not use any information from other agents (i.e. decentralised execution ).

This post builds upon my previous posts, deep deterministic policy gradients (DDPG) and Deep Q-Network, so it is best to review some of the core concepts such as experience replay, fixed target network and actior-critic there. We will go over them rather quickly here.
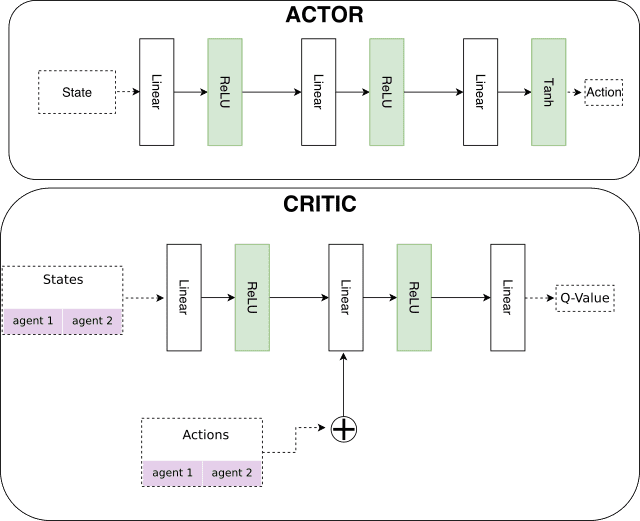
- The Actor network takes state as input and returns the action to take in the environment
- The Critic network, Deep Q-Network, takes the state and action of all agents as input and returns the action-value (Q-value)
- The Critic and Actor networks are trained by sampling experiences from the replay buffer.
- The action-value from Critic is used to teach the Actor to choose better actions.
The key improvement over the DDPG approach is that we now share the actions taken by all agents to train each agent (see maddpg.py to review the code).
Network Architecture
Similar to the previous post, we use fully connected layers for both Actor and Critic networks.

Hyper parameters
I tried several hyperparameters in order to solve the environment and the following worked the best for me.
| Parameter | Value | Description |
|---|---|---|
| BUFFER_SIZE | 100000 | Replay memory buffer size |
| BATCH_SIZE | 512 | Minibatch size |
| GAMMA | 0.95 | Discount factor |
| TAU | 1e-2 | Soft update of target parameters |
| LR_ACTOR | 1e-3 | Actor learning rate |
| LR_CRITIC | 1e-3 | Critic learning rate |
| WEIGHT_DECAY | 0 | L2 weight decay |
| SCALE_REWARD | 1.0 | Reward scaling (1.0 means no scaling) |
| SIGMA | 0.01 | OU Noise standard deviation |
| LEARN_STEP | 1 | How often to perform learning step (i.e after episode) |
| CLIP_GRADS | True | Should we clip gradients |
| CLAMP_VALUE | 1 | Gradient Clip value (e.g a value of 1 gets set as -1,+1) |
| FC1 | 64 | Input channels for 1st hidden layer |
| FC2 | 64 | Input channels for 2nd hidden layer |
Performance
The environment is considered solved when the average reward over 100 episode is +0.5. In the plot below, we can see that MADDPG solved the environment in half the number of episodes as compared to DDPG version and its training was a lot more stable.
Future work
We solved the environment using general-purpose multi-agent learning algorithm. The environment was solved in fewer episodes in comparison with deep deterministic policy gradients solution (see DDPG Report on github). I found that training was very sensitive to soft update parameter (TAU), discount factor (GAMMA), gradient clipping and number of steps in an episode. The following could be explored to improve training stability and performance:
- use prioritized experience replay to give more importance to experience tuples that can provide high expected learning progress
- experiment further with learning rates and introduce weight decay (currently set to 0) to speed up the learning
- implement ensemble policies to improve training performance (details below)
The Multi-agent reinforcement learning suffers from environment non-stationarity problem because the agent(s) policies change during the training. This could lead to agents learning the behaviour of their competitors which is undesirable because they may fail when competitors alter their strategies. The paper suggests that we can tackle this issue by making use of ensemble of policies where each agent trains a fixed number of sub-policies and at each episode a random policy per agent is chosen to execute the actions. This way, the agent and its competitors use one of the sub-policies at each episode.
The code along with model checkpoint and DDPG version is available on my github repository.