Facial Recognition
In this post, we explore facial recognition using deep learning. We will start with a high-level overview of network architecture and quickly move into its applications and possibilities.
The network architecture was proposed by Schroff et al in the Facenet paper. The key contribution of their paper was to introduce an end-to-end system that utilizes deep learning architecture to learn the mapping from the facial image to 128d vector, i.e embedding. This results in very high representational efficiency because a facial image can now be represented by 128 bytes. This is very efficient in terms of space and compute because we can store the images in compressed embedding form and use them later for inference. The original images are no longer required during inference and can be discarded. The operations on lower dimensional embeddings require less compute than original images (width, height, channel) matrix.

In order to train the network, they use TRIPLET LOSS where three images are used:
- Anchor: source image that will be converted into embeddings
- Positive: a different image of the same face and
- Negative: a different image of the different face
The triplet loss minimizes the distance between an Anchor and the Positive and maximizes the distance between Anchor and the Negative image. For more details, please refer to the paper in references.
On to the applications. The most obvious use case is to perform facial recognition where the app uses previously saved embeddings to compare against a new photo, video or realtime camera feed.
Facial Similarity
We could apply the idea of comparing face embeddings to some fun projects such as, given the face of an unknown person as input, show me the top three nearest embeddings from our embeddings database. Sometime last year, I told a friend about a toy classifier that I had built using neural networks (dog breed classifier). His immediate response was “why not build an app that can tell you the name of the actor you resemble ?”. Well, here it is:
Which Movie star do you resemble?
The idea is straightforward. We ask the user to upload an image, the classifier extracts the face, converts into the embedding vector and ranks it against all the actor embeddings.
The bigger the embedding universe the better the chances of finding someone close enough. The similarity is performed by taking the distance (euclidean norm) between the source (i.e embedding of uploaded image) and the actor vector (i.e embedding of each actor) and choosing the k nearest ones. In order to improve the search quality, we also apply a threshold on distance such that images with a distance greater than the threshold are dropped. The threshold is another hyperparameters that can be played with if it is too tight (i.e closer to 0) we may filter out almost all the embeddings and if it is too wide (i.e close to 1) the quality of prediction may suffer.
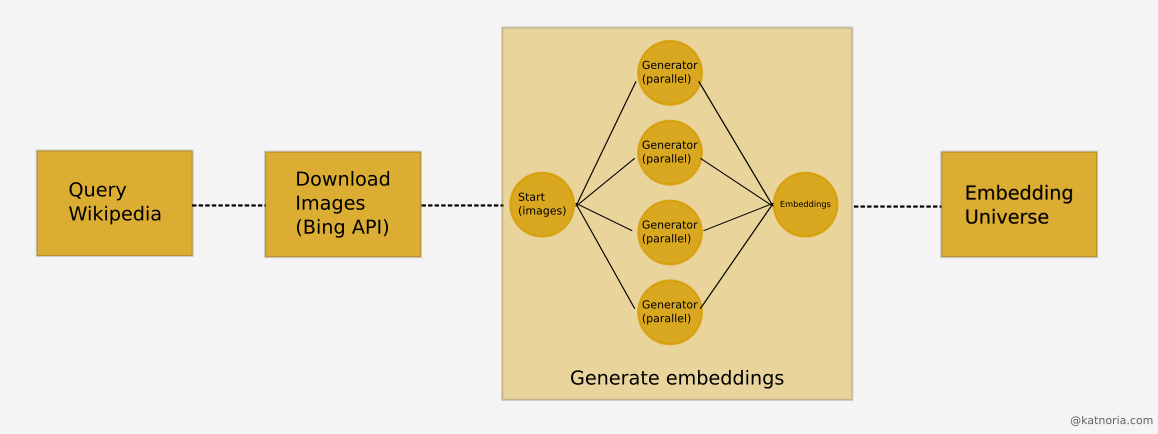
Based on the above idea, I built a fun little webapp that you can try online. The actor data was acquired by querying wikipedia for names and bing image search for lookup and download. After that, the images were run through the face extraction process to extract faces and embedding generator to generate and save embedding for each image.
The webapp is hosted on space and compute constrained virtual machine but still performs alright in my limited tests. You should use the front facing images and ideally try with multiple images to test the model. It seems the model pays more attention to nose and eyes compared to other facial features. We can also check its accuracy by testing it against the photo of a known actor.
In this example, I use the picture of Javier Bardem to find the faces similar to his and we see that model returns Jeffrey Dean Morgan as the nearest match. A very good match in my opinion, they do look similar. There is no Javier Bardem in the results because the wikipedia query, used to prepare the actor dataset, did not yield his name in the list of hollywood actors.
Next, I use a popular selfie by Ellen Degeneres to identify the faces and their nearest match. The model is able to identify all the actors:
Similarity between family members
The narrative goes like this:
A distant relative during one of the family gathering: “Kids…they grow fast. By the way, Yours looks more like your wife”
Yet another distantdistant relative (nodding): “Well actually, the kid looks more like you”
How many of us have heard that before? Well, we can use the same idea of comparing image embeddings in the vector space but this time instead of comparing with actors, we compare with in the family members.
In the video here, I try my demo app on Will Smith and his family.
Monitoring employees
No, Scratch that, we’re only talking about fun projects.
Or in fat Tony’s words “fuhgeddaboudit”
Robot Vision
Give vision to your DIY robots, train them to recognize you and the world around. Bonus, amaze and inspire the little ones.
In this video, I trained the model to identify my face along with a few from my photo library. This was done by first running the facial detection on all the images in my library and generating the embedding for every face. The embeddings were then labeled semi-automatically by first clustering the embeddings and labelling each cluster (or a few clusters) using Dash powered UI (Perhaps a topic for a future article).
Custom slideshows
Similar to iPhone memories but on photographs that are not in the iPhotos library for better or worse. You’re planning to surprise your grandmother by throwing her a birthday party and you want to create an awesome slideshow to show her journey through the photos. Now, you can either sift through the giant photo library of yours (big data), carefully choosing the photos that include your grandmother and sometimes taking a detour to a holiday album, or you can harness the power of deep learning (compute time/power not included) and let it filter the images for you. You can go one step further and combine textual search to filter the images further. It is quite possible to see something like this implemented in image organization software in near future.
Screen Time
Let’s say you work at the movie production house and you are tasked to find the screen time of all the actors in a Movie (for some analysis).
We can make use of the same facial recognition model. Here, instead of loading the entire embedding universe of actors, we can just load the embeddings of the main cast or generate if it doesn’t exist and label all the faces found in the movie. The unrecognized faces can either be discarded or labeled using unknown_n where n is the counter (e.g unknown_1, unknown_2).
Let’s try it out on a recent trailer from Mission Impossible: Fallout:
Screen Time Results:
- Tom Cruise: 39.17%
- Sean Harris: 15.88%
- Rebecca Ferguson: 9.35%
- Alec Baldwin: 8.16%
- Simon Pegg: 7.12%
- Henry Cavill: 5.64%
- Angela Bassett: 5.34%
- Ving Rhames: 5.19%
- Vanessa Kirby: 0.3%
Based on total number of frontal faces found in the video
Video Search
Once could use facial recognition along with object and scene detection to provide a rich video search on video platforms such as Netflix or Apple Movies. When watching reruns, you may not want to watch the entire show or movie but just parts of it.
For example, Siri on Apple TV.
User: Hey Siri, show me the scene where Neo is offered to choose between the Red and the Blue pill in Matrix?
Siri: Hang on, let me check with Alexa.
There is a lot to unpack for Siri to provide a meaningful search result. It has to understand that Matrix is the name of a movie, Neo is a character in the movie, the movie has frames with colored pills and the location of frames where Neo and pills appear together or within a threshold window. The possible solution would probably require more than the geometric (Computer vision, NLP, NLU) artificial intelligence.
Conclusion
At the moment, facial recognition performs best on the frontal face and fails or performs poorly on side pose. I expect this limitation to go away in the near future because this seems to be an area of active research but perhaps largely proprietary because I didn’t have any success on Arxiv.
This technology does open up a huge market.
Facial recognition can allow product companies to build better UX where such tools can be used to aid human collaborator or the user. The examples include image organization, in-video text/voice based search, home security, personalization (e.g Cozmo robot can recognize me), authentication (iPhone/Surface face unlock).
But it will also be used by agencies and companies for surveillance, tracking, marketing and revenue generation. One such example could be shopping mall cameras making money by tracking your movements inside the mall and selling it to the shops that can afford the subscription, shops using it along with eye tracking software to monitor the products you glance and provide personalized pricing to convert the glance into a buy (glance-thru conversion rate ? ).
Are we there yet?
REFERENCES
[1] FaceNet: A Unified Embedding for Face Recognition and Clustering [PDF]
[2] OpenFace [website, Arxiv]
[3] High Quality Face Recognition with Deep Metric Learning [website]
[4] DeViSE: A Deep Visual-Semantic Embedding Model [PDF]