A Simple Guide to Crowd Density Estimation
In this post, we are going to build an object counting model based on simple network architecture. Although we use the crowd dataset here, a similar solution can be applied to the rather more useful applications such as counting cells, crops, fruits, trees, cattle, or even endangered species in the wild.
There are different ways to count the object(s) in a given image. One could make use of R-CNN based models for object detection as shown in the example below:

Object detection and semantic segmentation
And that would work just fine, but what do you do when you have a lot more people such as Figure 1? Will the same assumptions hold true? Do we have access to the labelled datasets that are in the format used by R-CNN and its variants?

Figure 1, source: ShanghaiTech Dataset
In this post, we are going to build models that attempt solve this using the pre-trained ConvNet as backbone and a regression head for counting the crowd.
The network architecture is simple enough that I think this could be called the “Hello World” of the crowd density estimation task (pardon my ignorance if you know of simpler ways).
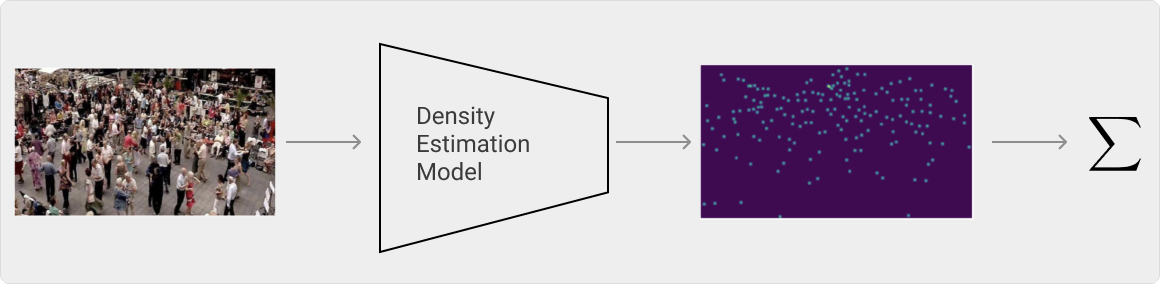
High Level Flow
If we overlay the output, i.e., the density map over the image, we can see that the head of each person is highlighted. These highlighted points are what we want our model to learn to estimate. And, to get the total count, we sum the points together.

Sample image and density map from ShanghaiTech Dataset
Dataset
We use the crowd counting dataset introduced in the paper “Single-Image Crowd Counting via Multi-Column Convolutional Neural Network”. The dataset is known as “ShanghaiTech Crowd Counting Dataset”, and it has images with arbitrary crowd density along with the target labels. We train our model on Part A of the dataset. However, instead of using density maps provided by the dataset, we use the processed maps generated by the C3 Framework for convenience purposes. The C3 Framework is an excellent resource that covers multiple network architectures and their performance on different datasets. I encourage you to have a look at the paper and their repo.
| Set | Total Images | Min People | Max People | Min Image Size | Max Image Size |
|---|---|---|---|---|---|
| Train | 300 | 33 | 3136 | (400,400) | (768,1024) |
| Test | 300 | 12 | 577 | (299,299) | (768,768) |
Histogram of train set
As you can see from the histogram, a large number of images have a crowd of less than 600.
Question: Does that mean the model trained on this dataset will not perform as well on the images with a large crowd?
Answer: You can use this notebook to ask this and other questions.
Below we show a few sample images from the dataset. We also show the associated density map below each image. Annotating the dataset must’ve been a difficult task.
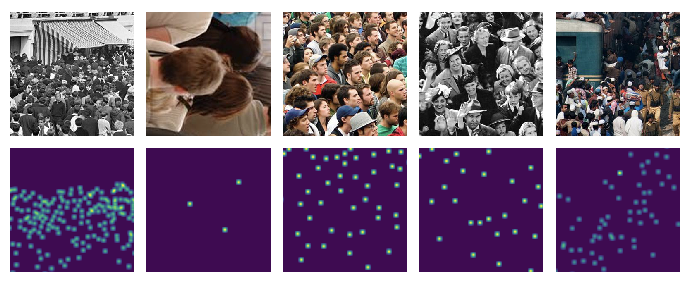
Dataset sample
Pre-processing
Throughout the implementation, we follow the guideline and techniques used by C3 Framework. The C3 framework uses the following augmentation/transformation:
CenterCrop (to 224) → RandomFlip → ScaleDown → LabelNormalize (100) → ToTensor → Normalize
# transforms
transforms.Compose([
CenterCrop(output_size=output_size),
RandomFlip(),
ScaleDown(factor), # Not used (currently set as 1)
LabelNormalize(),
ToTensor(),
Normalize()
])
Models
We will use VGG16 as the backbone for our models in this post. Once we have the full training and evaluation infra ready, we can easily add more powerful models and compare its performance against the baseline models.
Baseline Model
As our baseline, we will use a pre-trained VGG16 network followed by 2 Conv layers and the upsampling layer to match the target density map (m x n). Recollect that we scale down the input image and target by a scaling factor, so the final layer needs to keep that in consideration.
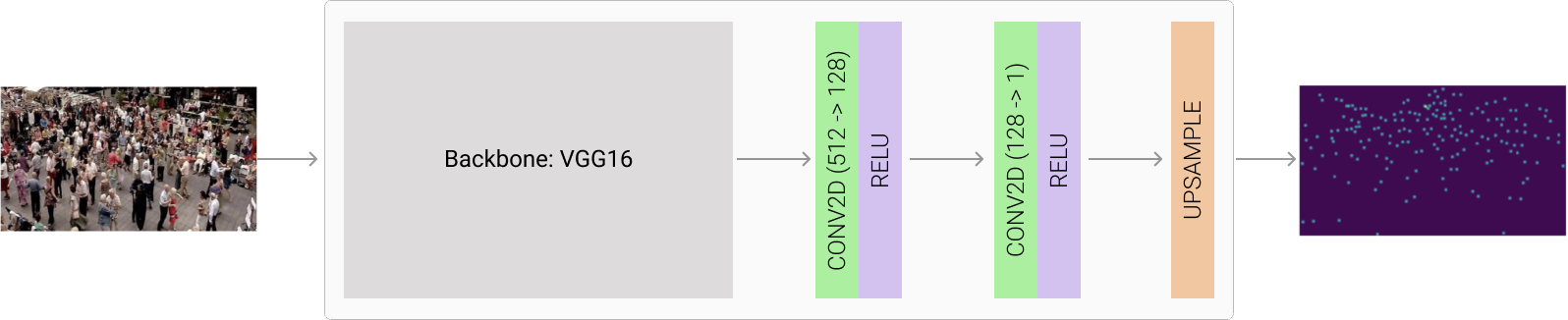
VGG16 Baseline Model
class VGG16Baseline(nn.Module):
"""Baseline model
Baseline model that uses a pre-trained VGG16 network as backbone
"""
def __init__(self, channels=[512, 128, 1], scale_factor=4):
"""
Parameters
----------
channels: Input channel size for all three layers
scale_factor: Factor to upsample the feature map
"""
super(VGG16Baseline, self).__init__()
self.scale_factor = scale_factor
conv_layers = list(models.vgg16(pretrained=True).features.children())
# Mark the backbone as not trainable
for layer in conv_layers:
layer.requires_grad = False
self.model = nn.Sequential(
*conv_layers,
nn.Conv2d(channels[0], channels[1], kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(channels[1], channels[2], kernel_size=3, padding=1),
nn.ReLU(inplace=True)
)
def forward(self, inputs):
""" Forward pass"""
output = self.model(inputs)
output = F.upsample(output, scale_factor=self.scale_factor)
return output
We train the baseline model using the ADAM optimizer with the learning rate of 1e-5 for 400 epochs. The choice of loss function to optimizer is Mean Square Error(MSE). We also track Mean Absolute Error (MAE) on tensoboard along with the MSE.
Evaluation
We will first check how well the model is able to overfit the training data. We visualize its performance by comparing the actual vs. predicted crowd count. The better the model, the more points lie closer to the diagonal line. As you can see in the plots below, the model does comparatively better for images with crowd ≤ 1000. However, its performance begins to suffer as the number of crowd increases.
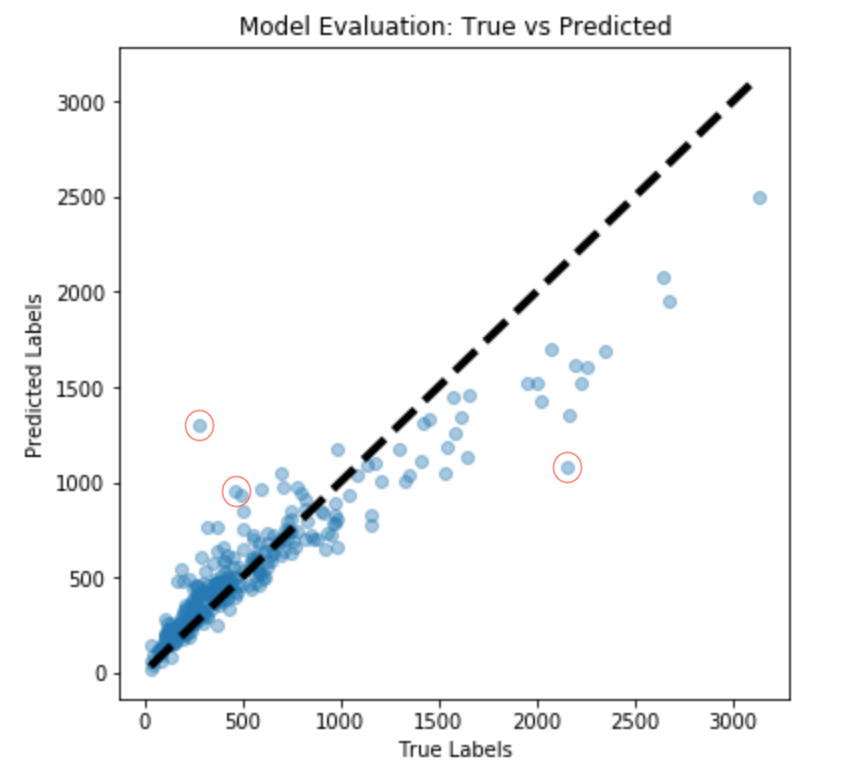
Train set performance
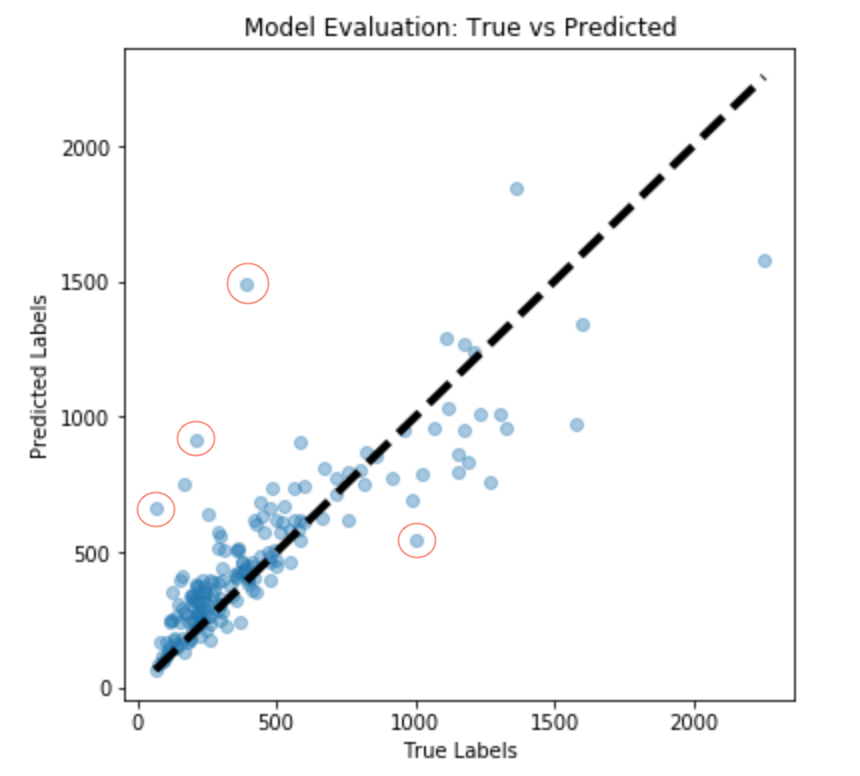
Test set performance
I find it quite useful to review the images the model gets right and the ones where it struggles. Here, we display the images from both the train and test set.

Train Set: Handpicked images from train set where the model does a good job

Train Set: Images where the model does a poor job (marked in the red circle in the plot above)

Test Set: Images where the model does a poor job (marked in the red circle in test set performance plot)
Two things stand out to me: 1) the images with better prediction only contain people 2) the orientation of the heads in the image. Another crucial insight is that as you increase the input image size, the model starts to perform better.
VGG16 with Decoder
We now move to another simple yet more powerful model that, too, uses pre-trained VGG16 as its backbone. We make use of CONV and CONVTRANSPOSE layers, the C3 paper refers to these layers as the decoder.
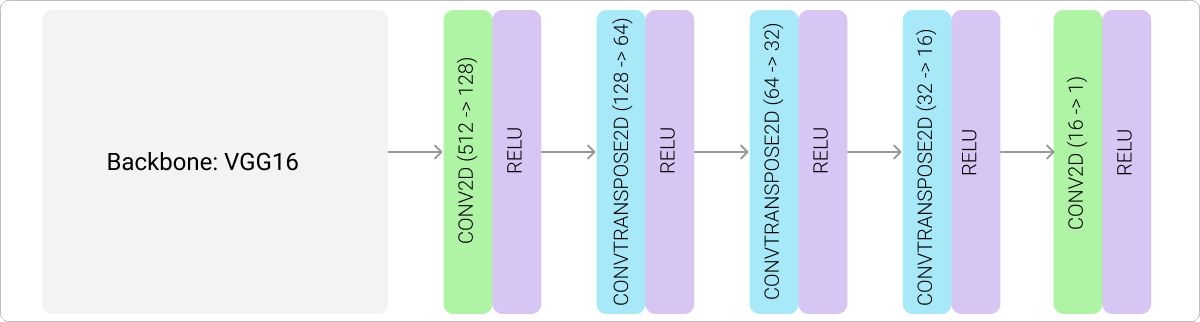
VGG16 + Decoder Model
class VGG16WithDecoderV2(nn.Module):
""" VGG16 Decoder"""
def __init__(self):
super(VGG16WithDecoderV2, self).__init__()
conv_layers = list(models.vgg16(pretrained=True).features.children())[:23]
# Pre-trained layers are not trainable
for layer in conv_layers:
layer.requires_grad = False
self.model = nn.Sequential(
*conv_layers,
nn.Conv2d(512, 128, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.ConvTranspose2d(128, 64, 4, stride=2, padding=1, bias=True, output_padding=0),
nn.ReLU(inplace=True),
nn.ConvTranspose2d(64, 32, 4, stride=2, padding=1, bias=True, output_padding=0),
nn.ReLU(inplace=True),
nn.ConvTranspose2d(32, 16, 4, stride=2, padding=1, bias=True, output_padding=0),
nn.ReLU(inplace=True),
nn.Conv2d(16, 1, 1, padding=0),
nn.ReLU(inplace=True)
)
def forward(self, inputs):
"""forward pass
Parameters
----------
inputs: Batch of input images
"""
output = self.model(inputs)
return output
We train this model with the same hyper parameters as the baseline model for 400 epochs.
Evaluation
Similar to the baseline model, we evaluate the VGG16 with Decoder on both training and test sets. The scatter plots below show the actual vs. predicted crowd count.
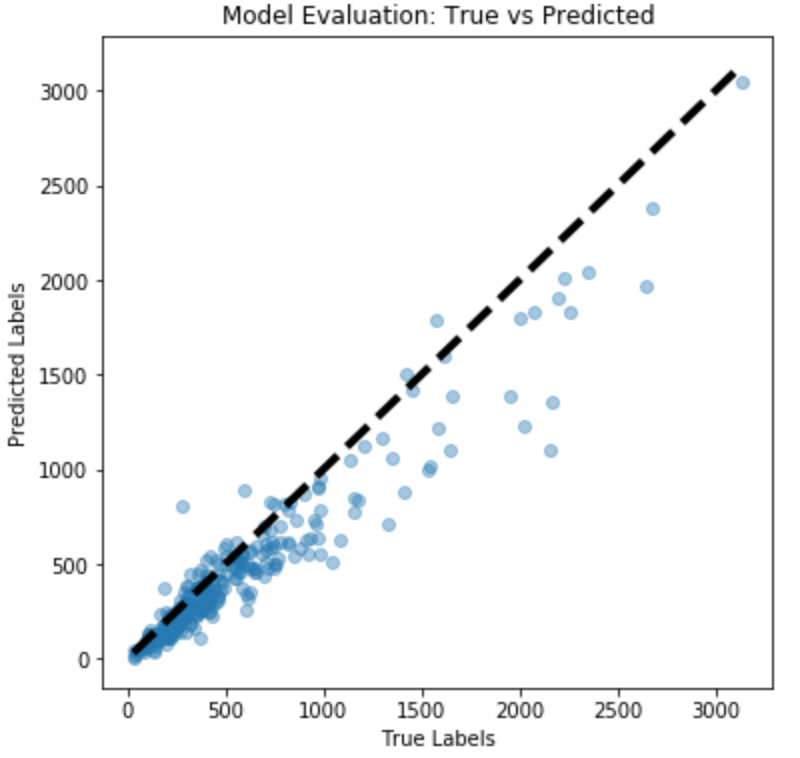
Train set performance (Decoder)
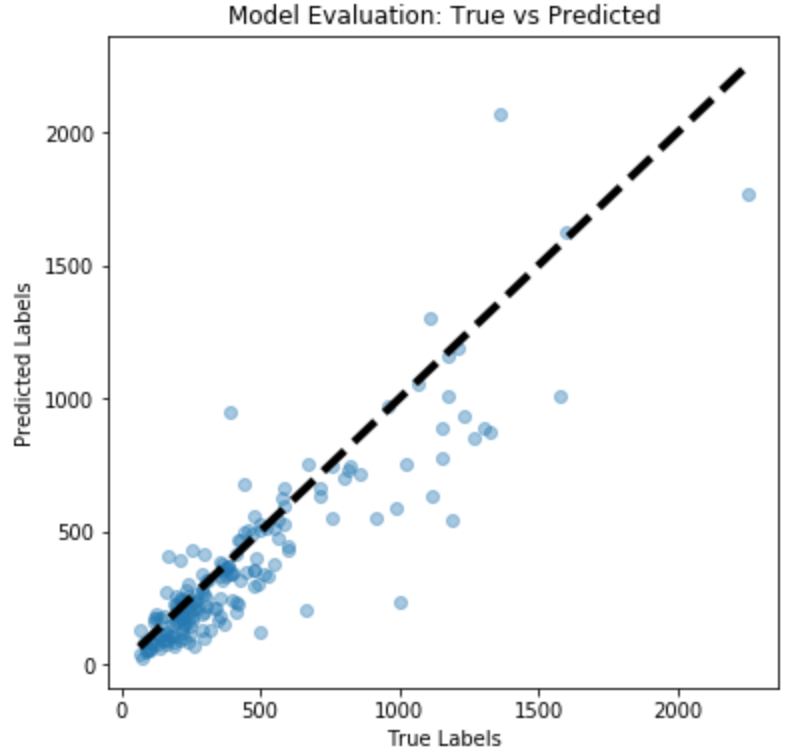
Test set performance (Decoder)
According to the C3 Framework, both the models will have comparable performance but VGG16 with Decoder will generate more precise density maps. We can see this in the table and examples below. Our numbers are no way near the ones reported by C3 Framework, which I mainly think is because they use a higher input size to train their models.
| Model | TRAIN: MSE | TEST: MSE | TRAIN: MAE | TEST: MAE |
|---|---|---|---|---|
| VGG16 Baseline | 144 | 706 | 6 | 13 |
| VGG16 Decoder | 129 | 650 | 8 | 14 |
And finally we overlay the density maps generated by both the models on a given image. We see that VGG16 Baseline is spot on in terms of the actual count but VGG16 + Decoder generates tighter density maps.

VGG16 Baseline

VGG16 + Decoder
Next, we show a more detailed plot to visualise the effect of input image size on both the models.
You can try increasing the input size and play around with the models yourself. If you can get good enough model, you can perhaps help answer the question on whose rally had more people. The code is available on my GitHub Repo. In case you haven’t noticed, if you hover over the cover image you will see the density map generated by VGG16 Decoder.
What Next
You can try tuning the hyperparameters, finding the right learning rate and or model architecture to get better performance. Here is the list of things I would try next if I were to make it useful:
- Add regularisation
- Use a powerful backbone such as Resnet variants
- Use other models from C3 Framework
- Given that we have only 300 samples (very low in terms of DL), you could try U-Net which is known to perform well on tasks such as cell segmentation
- Spatially divide the image into sub-regions called closed sets, train the model on closed sets as suggested by the paper “From Open Set to Closed Set: Counting Objects by Spatial Divide-and-Conquer”. The authors claim that this approach generalised well and can achieve the state of the art performance on a few crowd counting datasets
- Use the encoder-decoder based approach highlighted in the paper “Encoder-Decoder Based Convolutional Neural Networks with Multi-Scale-Aware Modules for Crowd Counting”. They claim that their model can perform well on dense as well as sparse crowds.
REFERENCES
[1] C3 Framework: I learned a great deal from this paper and their code [PAPER | GITHUB]
[2] A Survey of Recent Advances in CNN-based Single Image Crowd Counting and Density Estimation [LINK]
[3] U-Net: Convolutional Networks for Biomedical Image Segmentation [LINK]
[4] From Open Set to Closed Set: Counting Objects by Spatial Divide-and-Conquer [LINK]
[5] Encoder-Decoder Based Convolutional Neural Networks with Multi-Scale-Aware Modules for Crowd Counting [LINK]